Новое исследование от Anthropic: как сделать так, чтобы все опасные знания хранились в модели отдельно от обычных
И снова про элаймент! Уж очень занятный в этот раз стартап предлагает подход. Называется он Selective GradienT Masking. Погнали разбираться.
Вообще, как такового элаймента на этапе претрейна не существует, все это добавляется уже после предобучения. А это довольно серьезный затык.
Пока единственный вариант, до которого люди додумались – это просто выбросить из датасета "опасные знания", но это (1) оч дорого и долго, потому что требует разметки; (2) отсекает дополнительно и много полезных знаний, и модель тупеет. Так что – ерунда.
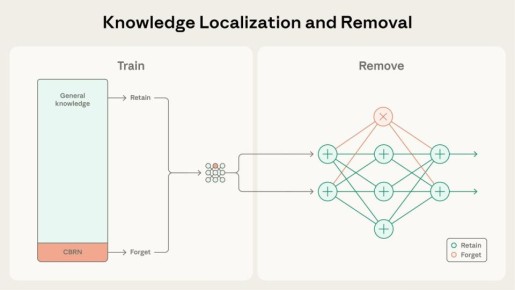
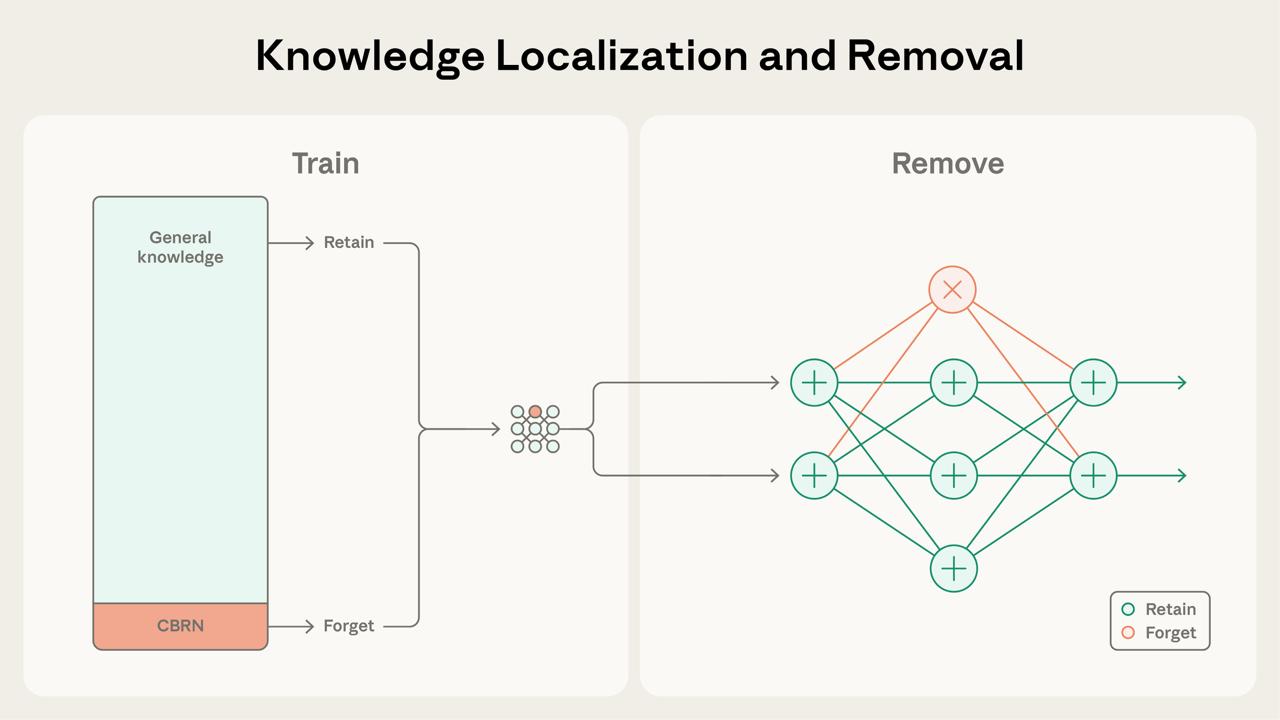
А вот Anthropic предлагают сами данные не трогать, а вместо этого сделать так, чтобы вся опасная информация стекалась в отдельный кусок параметров, который затем можно просто... удалить. Работает это так:
– На каждый блок трансформера мы дополнительно надеваем голову внимания, которую помечаем, как "forget" параметры.– Если на вход попадают данные, которые помечены, как "опасные", мы насильно зануляем все градиенты, кроме "forget". Это гарантирует, что все опасные знания стекаются в определенное место.
– Чтобы после модель могла хорошо работать без этих параметров, на части данных при прямом проходе им зануляют активации.
Как видите, это, по факту, та же самая фильтрация данных. Только умная. Во-первых, такой подход устойчив к шуму разметки. Во-вторых, метить все данные потенциально необязательно: выяснилось, что начиная с какого-то момента даже неразмеченное опасное содержимое датасета начинает тяготеть больше к "forget" параметрам. Это назвали эффектом Абсорбирования.
При этом модель после вырезания этой вот черной душонки глупеет меньше, чем при вырезании данных из датасета. Все-таки здесь мы действуем немного деликатнее. Ну и ведет она себя после этого так, как будто ей действительно ничего подобного никогда не показывали, а не как будто она временно об этом забыла.
В общем, на уровне механики и идеи – довольно интересный зачаток
https://alignment.anthropic.com/2025/selective-gradient-masking/